Routine optimization aims to improve a formula’s accuracy but often overlooks its precision. It focuses on bringing the formula’s average error to zero without addressing the control of its spread. Could we design an optimization method that enhances both accuracy and precision? This page is dedicated to exploring that question and offers a resounding ‘yes.’ This page echoes a recent publication that outlines the principles and results of this approach.
Introduction
The performance of an intraocular lens (IOL) power calculation formula depends on its precision and accuracy. In the context of IOL power calculation formula evaluations, the error is defined as the difference between the actual postoperative refractive outcome (obtained through measurement) and the predicted refractive outcome. These evaluations are typically conducted post hoc, meaning they are performed after surgery by comparing the predicted refraction with the actual refraction achieved in the patient. Accuracy refers to how close the predicted refractive outcome of the IOL power calculation is to the actual postoperative refractive outcome. In other words, a formula is accurate if, on average, the prediction errors are centered on zero. A high accuracy means the mean prediction error is small, meaning the formula’s overall bias is low. Precision refers to how consistently a formula can predict refractive outcomes across different cases. A formula is precise if the prediction errors are closely clustered around the average result, regardless of whether the mean is centered perfectly at zero. High precision means that the standard deviation (SD) of the prediction errors is small. Accuracy measures how close the average prediction is to the true result (bias).Precision measures how tightly grouped the prediction errors are (variability).An ideal IOL formula would be both accurate (minimal bias) and precise (minimal variability). To begin, it’s worth delving into the mechanisms behind optimization.
Routine Optimization in Clinical Practice
Conditions for Optimization
To optimize a formula, it is necessary to collect postoperative refraction data from a sufficient number of eyes operated for cataracts (that would represent a realistic distribution of IOL powers to achieve meaningful results in a given context). Once this data is gathered, it can be compared to the refraction predicted by the formula used to calculate the power and type of the implant placed. If the actual refraction matches the predicted one, the formula has not made an error. However, if there is a discrepancy, it indicates an error, which can be either positive (the formula predicted a more myopic or less hyperopic refraction) or negative (the formula predicted a less myopic or more hyperopic refraction).
Purpose of Optimization
Once these differences are calculated for each eye, it is possible to compute the average of these differences between the obtained and predicted refraction. If this average is not zero, it means the formula is affected by a systematic bias. The goal of optimization is to eliminate this bias and bring the average error to zero. It’s important to understand that the performance of an IOL power calculation formula can only be properly assessed after performing this type of optimization. After correcting the average error, various metrics, such as standard deviation or the mean absolute error, are calculated to evaluate the formula’s precision further. A dedicated page discusses these metrics in detail and their significance. This makes it clear why optimization is a crucial step to improve the performance of a formula in cataract surgery.
Method Used to Eliminate Systematic Bias
Optimization is carried out by adjusting a constant, which uniformly increases or decreases the predicted effective lens position (ELP). We have developed a formula that allows us to predict the refractive change induced by a shift in position (i.e., a change in the formula’s constant): ΔR = 0.0006 × (P2 + 2KP) ΔELP Where:
- R is the refraction in the spectacle plane,
- P is the power of the implanted IOL,
- K is the corneal power (in diopters), and
- ELP is the effective lens position (in mm) change (constant adjustment)
The shift in position, which is the same for all eyes, leads to the necessary power adjustment (which is different for each eye) required to correct the average prediction error.
ΔR Calculation Example
Given the formula:ΔR = 0.0006 × (P2 + 2KP) × ΔELPWhere:
- P = 23
- K = 43
- ΔELP = 0.5
Let’s calculate ΔR step by step:
- Calculate P2:
P2 = 23 × 23 = 529 - Calculate 2KP:
2KP = 2 × 43 × 23 = 1978 - Add P2 and 2KP:
529 + 1978 = 2507 - Multiply by 0.0006:
0.0006 × 2507 = 1.5042 - Multiply by ΔELP:
1.5042 × 0.5 = 0.7521
Result: ΔR = 0.7521 D for a 0.5 mm ELP change in an eye with K=43 D and implanted IOL power 23D.This formula highlights the significance of the implant power in the refractive impact of an ELP variation.For an IOL of 1D, the calculation would lead to : ΔR = 0.0129 DFor an IOL of 35D: ΔR = 1.071 D (about 80 times more). Here is a plot displaying the relationship between ΔR and ΔELP:
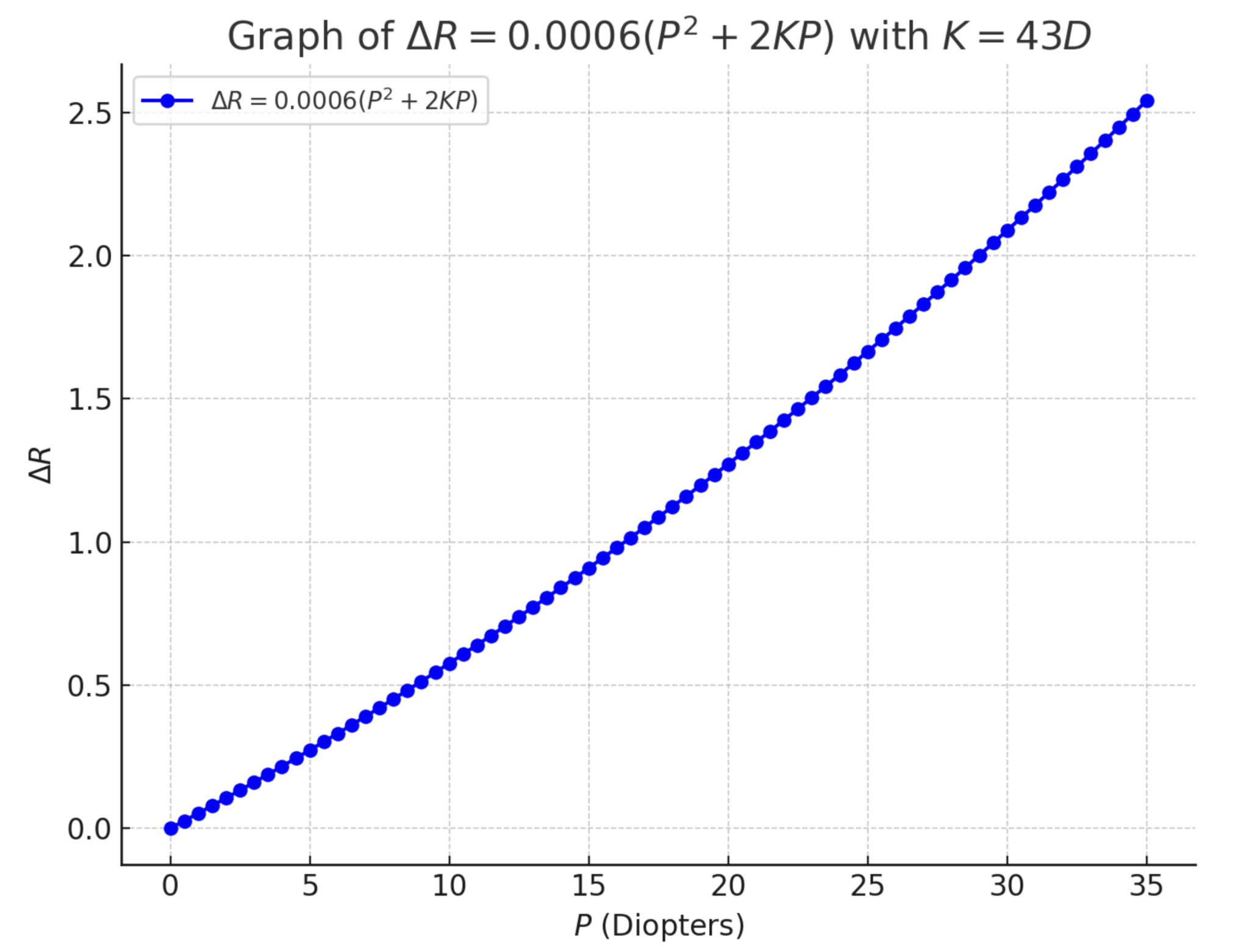
This formula reveals an important point: for the same change in the constant, the variation in refraction will be about 50 times greater in an eye with a 35 D implant compared to an eye with a 1 D implant. Additionally, the distribution of implant powers in a large sample of operated eyes is not uniform; most samples of operated eyes have far more implants with powers close to 22 D than those with very low (<10 D) or very high (>30 D) power. Nevertheless, the adjustment of the constant must take into account the eyes with high-power implants. In contrast, the contribution of low-power implants is negligible (their refraction is not significantly affected by a change in the constant).
Consequences of Optimization by Constant Adjustment
At this point, it’s crucial to recall the goal of optimization: it does not aim to reduce the formula’s error in terms of precision (i.e., the spread of errors within the sample). Rather, it focuses on centering the average error around zero. This scenario is depicted here:
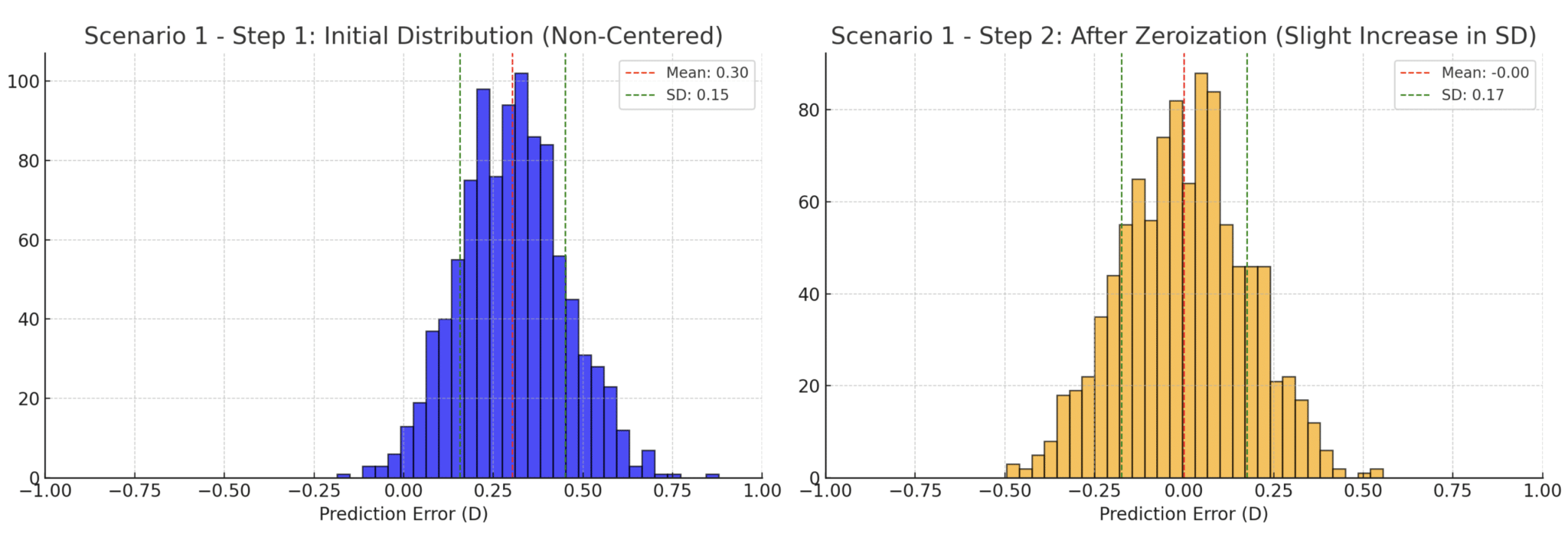
Imagine a formula that systematically makes the same positive error for every operated eye: in an ideal scenario, optimization should reduce or eliminate the error for each eye. However, because the method relies on shifting the predicted implant position, it becomes clear that it’s impossible to significantly alter the refractive error for eyes with low-power implants unless an ELP prediction error exclusively causes that positive error, as their positional shift doesn’t significantly affect the eye’s refraction. This means that errors of the opposite sign (negative, in this example) must be induced in eyes with high-power implants. This necessity inherently increases the standard deviation (SD) of refractive error. In clinical practice, it is unlikely that the same error will occur consistently because prediction errors are multifactorial. However, in the hypothetical scenario, we imagined, this would correspond to a « perfect » formula that only made a simple mistake in estimating keratometric power, leading to, for example, a 1 D overestimation of corneal power. A reduction in the predicted implant power would be expected. This would cause a consistent positive prediction error across all eyes in the sample, resulting in an SD of nearly zero. Using the classical optimization method, however, would significantly increase the SD, as illustrated in the graph below.
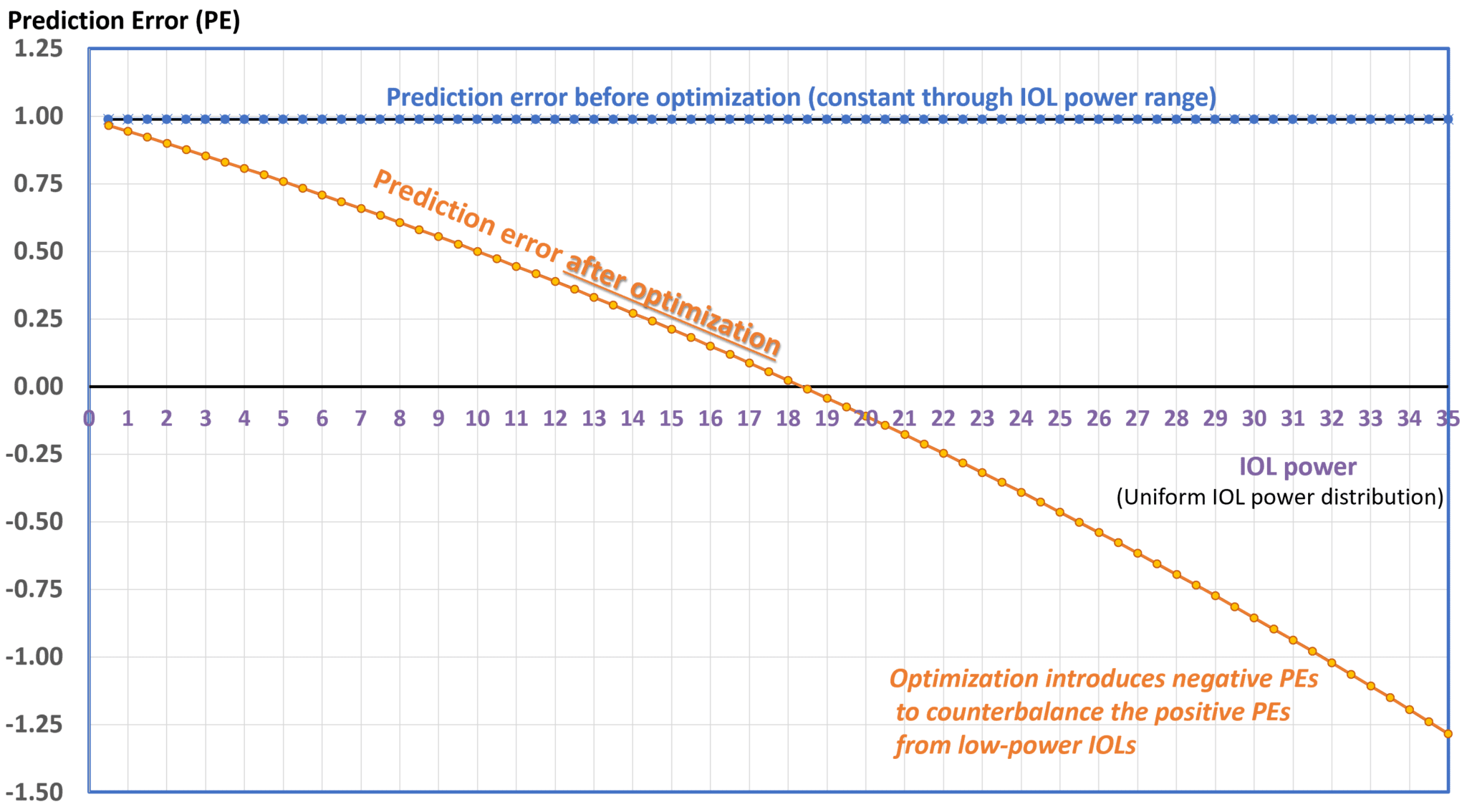
The representation can now be made for a distribution representative of the implanted lens powers, which peaks around powers close to 21 D.
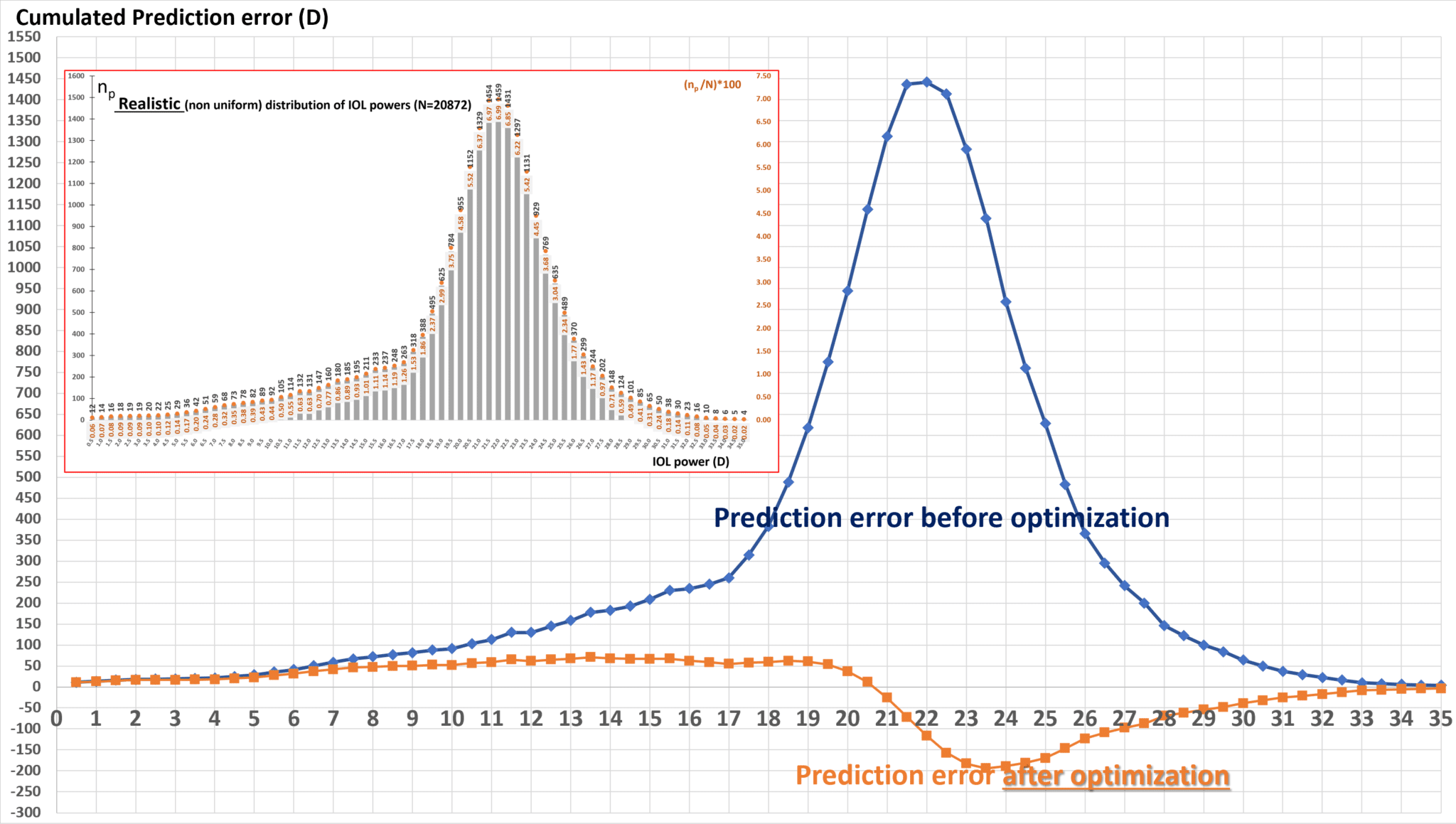
In reality, the sources of error are multifactorial, but there is reason to believe that most third- and fourth-generation formulas tend to overestimate corneal power on average. This misestimation plays a significant role in explaining part of the distribution of prediction errors. Moreover, the consequences of zeroing the average error had not been fully explored until recently, when we published a study showing that, depending on the source of the error in the formula, the impact on SD can vary greatly. For instance, when optimization is driven by an error in corneal power, adjusting the constant leads to a significant increase in SD. On the other hand, correcting errors related to ELP or axial length could either decrease (ELP) or keep the SD relatively constant (axial length). A page is dedicated to the theoretical consequences of the classic optimization techniques on the precision of IOL power formulas. The error in an implant calculation formula is complex, but a significant portion is undoubtedly related to the incorrect estimation of corneal power. It seems logical to compensate for a systematic error in corneal power estimation with a specific constant adjustment. This principle forms the basis of our proposal for better optimization of implant power calculation formulas, which primarily aims to reduce systematic biases by applying a corrective adjustment that better accounts for the source of prediction errors.
Optimizing Accuracy and Precision
Based on the principles outlined above, an alternative to the classic optimization approach can be considered. This method focuses first on minimizing the standard deviation (SD) by adjusting a positional constant without worrying about the mean prediction error at this stage. Once the SD is minimized, any remaining mean error can be zeroed out by adjusting a keratometric constant, whose value is set to the opposite of the residual mean error (in the corneal plane). This adjustment of the keratometric constant does not significantly impact the SD because it shifts the residual error of each eye by the same refractive (not positional) increment.
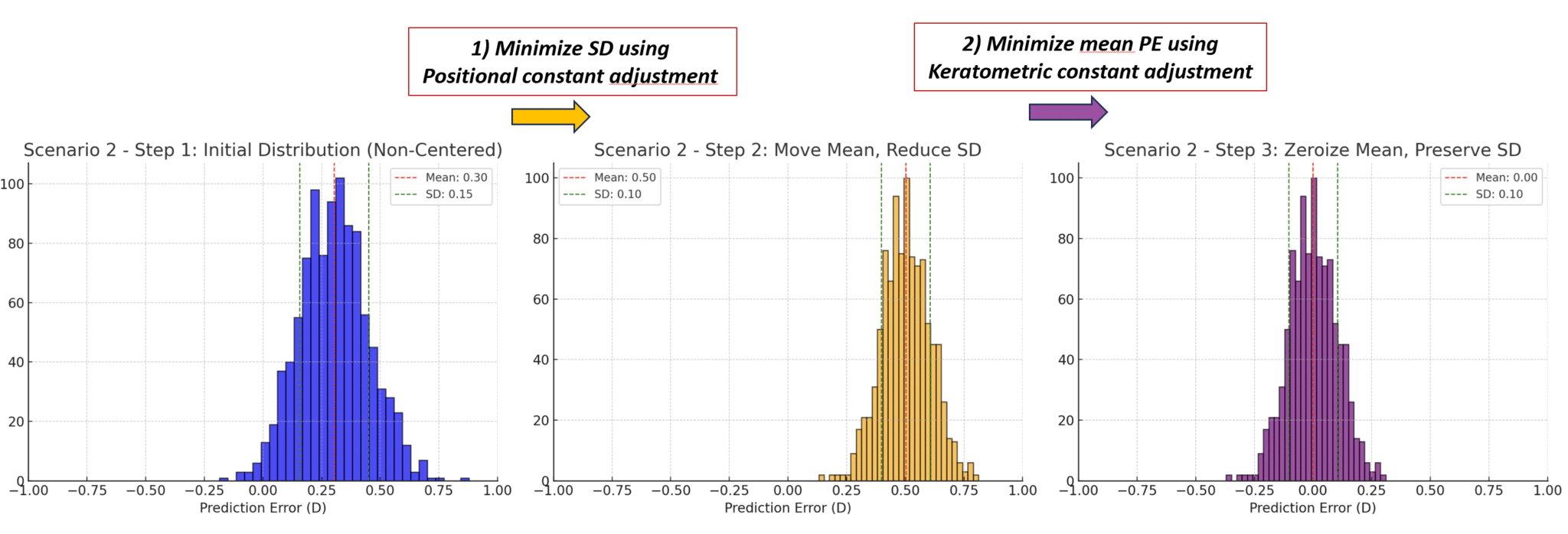
This approach is grounded in the expected impact of different sources of prediction errors in formulas: positional errors cause a prediction error proportional to the squared power of the implanted lens, whereas corneal power measurement errors affect all eyes by the same magnitude of error. To apply this method, it is essential to be able to determine the value of the adjustment needed to minimize the SD.
Determining the Constant to Minimize the SD
In a recent study, we developed a formula that calculates the necessary positional constant adjustment to minimize the SD (an example is provided at the end of the page) ΔELPSD = – ∑i=1N(Fi – F̄)(Ei – Ē) / ∑i=1N (Fi – F̄)2 Where:
- ΔELPSD is the change in the effective lens position (ELP) to minimize the standard deviation.
- Ei is the prediction error for the i-th eye.
- Ē is the average prediction error across all N eyes.
The variable Fi is calculated using the following formula Fi = 0.0006 (Pi2 + 2KiPi) Where:
- Pi is the power of the implanted intraocular lens for the i-th eye.
- Ki is the corneal power for the i-th eye (in diopters).
Fi represents the slope value that links, for a given eye, the displacement of the implant due to the increment (in mm) and the resulting change in refraction. It equals 1.43 in an eye that has received a 22D IOL and has a 43D cornea. The average power F̅ (F-bar) is the mean value of all Fi values across the sample of N eyes, calculated as: F̅ = (1/N) ∑i=1N Fi Experts will recognize the formula for the covariance between the prediction error and F in the numerator, and the variance of F in the denominator. Since F is highly dependent on P (the power of the implant), we can understand that the adjustment of the constant to minimize the standard deviation (SD) is influenced by the impact of implant power on the prediction error. To explain further, the covariance measures the relationship between two variables — in this case, the prediction error and the implant power (through F). If the covariance is high, it means that changes in implant power tend to result in significant changes in the prediction error. In our context, minimizing the SD involves adjusting the constant to reduce the spread of prediction errors across different eyes. Because the prediction error is closely linked to the implant power, this adjustment essentially compensates for the influence that power has on the error, making the formula more precise. The constant helps to reduce this variability, ensuring that the SD (which measures the dispersion or spread of errors) is minimized. In summary, the more the prediction error and implant power are correlated (i.e., higher covariance), the more significant the adjustment needs to be in order to minimize the SD. This formula was derived from the equation linking changes in position with changes in refraction (see above). Shifting all implants by a constant increment induces a refractive variation that heavily depends on the power of the implanted lens in each eye of the sample. This adjustment is calculated so that this variability helps reduce the spread of prediction errors. In doing so, it mainly addresses positional errors, which have effects that are proportionally linked to the lens power. Except in a theoretical scenario where prediction errors stem solely from a uniform ELP (effective lens position) prediction error across all eyes, there is no reason to expect the residual mean prediction error after SD minimization to be zero. Zeroing this residual error without increasing the SD is necessary. This can be achieved by adjusting a keratometric constant designed to shift the refractive value by an amount equal to the opposite of the residual mean prediction error across all eyes, thus zeroing out the mean prediction error.
Determining the Keratometric Constant to Zero the Residual Mean Error
The keratometric constant (let us call it R) modifies the keratometric power by an increment equal to the opposite of the residual mean error after SD minimization. As an example, if the mean prediction error in the spectacle plane is +0.23 D, the same value can be considered for the corneal plane. Therefore, to eliminate the remaining mean prediction error after minimizing the standard deviation (SD), a correction of -0.23 D should be applied to the keratometric power estimation for all eyes. This keratometric constant can be seen as a corrective factor that adjusts for any potential systematic bias in the estimation of keratometric power by the given formula. Its use helps prevent an increase in error dispersion that would result from a positional adjustment aimed at compensating for the variance in error related to keratometry. This approach should enhance the performance of formulas whose assumptions about corneal power estimation suggest a tendency to overestimate it (such as using an overly high keratometric refractive index, see here and here). With this sequence, the root mean square (RMS) error is minimized, as it is equal to the square root of the sum of the variance (the square of the SD) and the square of the residual mean error, which becomes zero using this optimization technique.
Impact of Standard Deviation Minimization in IOL Power Formulas
We recently conducted a study aimed to determine if prioritizing the minimization of standard deviation (SD), which improves precision, could lead to better clinical outcomes compared to traditional methods that focus on zeroing the mean prediction error (PE). Precision, measured by a low SD, ensures prediction errors are closely clustered, which is critical for consistent postoperative results. A retrospective analysis was conducted on a primary dataset of 4885 eyes from 2611 patients, with a secondary dataset of 262 eyes from 132 patients for validation. Four IOL power formulas (SRK/T, Holladay 1, Haigis, and Hoffer Q) were evaluated in a two-step process:
- Minimization of SD: New constants were introduced to reduce SD before adjusting the mean PE.
- Adjustment of Mean PE: After SD minimization, the mean PE was zeroed using biometric adjustments (shifting the predicted refractions by the opposite of the residual mean PE).
The effectiveness of these new constants was assessed through statistical analysis, measuring metrics such as mean absolute error (MAE) and the percentage of eyes with prediction errors within specific ranges.
Primary dataset:
Prioritizing the minimization of the standard deviation (SD) had a measurable impact on the precision of certain formulas. Specifically, the Haigis and Hoffer Q formulas demonstrated a statistically significant reduction in SD:
- Haigis: SD reduced from 0.3914 to 0.3846.
- Hoffer Q: SD reduced from 0.4107 to 0.4033.
These reductions indicate that the adjustment of the constant effectively minimized the spread of prediction errors, thereby enhancing the precision of these formulas. In contrast, the Holladay 1 and SRK/T formulas did not show an improvement that was not statistically significant, highlighting potential formula-specific limitations when applying this optimization method.
Validation Set Analysis
The results from the secondary dataset (used for validation) mirrored those of the training set, confirming the reliability of the approach: Haigis: SD reduced from 0.3255 to 0.3153. Hoffer Q: SD reduced from 0.3521 to 0.3387. These improvements in SD reflect greater precision, translating into tighter clustering of prediction errors around the target refractive outcomes. As in the training set, the Holladay 1 and SRK/T formulas did not show significant changes in precision. This suggests that while SD minimization is beneficial for some formulas, its effectiveness may be limited for others. This section highlights a fundamental shift in how we approach IOL power formula optimization. By minimizing the SD before adjusting the mean prediction error (PE), we can improve the formula’s precision, ensuring that the errors are more tightly clustered around the target value. While the Haigis and Hoffer Q formulas showed notable improvements, the minimal response from Holladay 1 and SRK/T suggests that some formulas may be less sensitive to this type of adjustment, at least on the sample of included eyes. This variability underscores the importance of developing formula-specific optimization strategies rather than relying on a one-size-fits-all approach. For formulas like Haigis and Hoffer Q, the improvements in SD mean that a higher percentage of patients are likely to achieve their target refractive outcomes within clinically acceptable ranges (e.g., ±0.25 D). This consistency is crucial for reducing extreme postoperative refractive errors and improving overall patient satisfaction. In practice, this method could lead to fewer patients experiencing significant deviations from their target vision, enhancing both visual outcomes and quality of life.
Conclusion: Optimizing Precision in IOL Power Formulas
These results demonstrate that focusing on minimizing SD can significantly enhance the precision of certain IOL power formulas. By reducing the variability in prediction errors, this approach ensures that more patients achieve their target refractive outcomes, leading to greater consistency and satisfaction in cataract surgery results. The method follows a mathematical logic when one fully understands the mechanisms of optimization. Initially, these mechanisms addressed the need to account for variations in implant design. However, today, a more comprehensive and deductive approach is required to advance in this field. Future studies should investigate broader applications of this method, test additional formulas, and validate the approach with larger datasets to confirm its clinical relevance. In summary, this innovative two-step approach—first minimizing SD, then adjusting the mean PE—offers a promising pathway to refining IOL power calculations and improving postoperative outcomes.
ΔELPSD Calculation Example
Given: a dataset of 3 eyes (all numerical values in dpt)
- Eye 1: E1 = 0.50, P1 = 24, K1 = 42
- Eye 2: E2 = -0.25, P2 = 13, K2 = 40
- Eye 3: E3 = 0.0, P3 = 27, K3 = 45
Fi = 0.0006 × (Pi2 + 2 × Ki × Pi)Calculated values:
- F1 = 1.0368
- F2 = 0.4662
- F3 = 1.2774
Average values:
- F̄ = 0.9268
- Ē = 0.0833
ΔELPSD = – ∑i=1N(Fi – F̄)(Ei – Ē) / ∑i=1N (Fi – F̄)2Numerator:
- (1.0368 – 0.9268)(0.50 – 0.0833) + (0.4662 – 0.9268)(-0.25 – 0.0833) + (1.2774 – 0.9268)(0.0 – 0.0833)
- = 0.0112 + 0.1136 – 0.0292 = 0.1702
Denominator:
- (1.0368 – 0.9268)2 + (0.4662 – 0.9268)2 + (1.2774 – 0.9268)2
- = 0.0121 + 0.2117 + 0.1228 = 0.3466
Final Calculation:
ΔELPSD = – 0.1702 / 0.3466 ≈ -0.491mm