16. IOL Power Prediction Error Metrics: PE, MAE, SD, RMSE
Introduction to Metrics for IOL Power Calculation Performance Evaluation
This page is dedicated to the metrics used to quantify and characterize the performance of intraocular lens (IOL) power calculation formulas such as mean Prediction Error, Standard Deviation (SD), RMSE, etc.
Predicting the optimal lens power to achieve target refraction is a complex process that relies on predictive models, which inherently involve assumptions and simplifications. To ensure the accuracy and reliability of these predictions, it is crucial to perform a detailed analysis of the errors associated with the formula’s predictions. This process helps identify areas where the model can be optimized and improved.
In any predictive approach, the goal is to minimize errors and refine the model. Analyzing the errors in IOL power calculation enables practitioners to improve the precision of predictions through various methods, such as adjusting constants, modifying the formula’s parameters, or applying optimization techniques to reduce bias and enhance accuracy. By doing so, the predictive performance of the formulas can be continually enhanced, leading to better clinical outcomes.
In this context, the ability to measure and assess prediction errors becomes vital. The metrics presented on this page, such as Prediction Error (PE), Mean Absolute Error (MAE), and Root Mean Square Error (RMSE), provide insight into both systematic biases and random variabilities in the prediction process. Understanding these metrics allows for a structured approach to optimizing IOL power formulas, ensuring that they perform as effectively as possible under different clinical conditions.
In the following sections, we will explore key statistical metrics used to evaluate the performance of IOL power calculation formulas. Each metric will be discussed in detail, providing not only its mathematical definition but also its practical significance in the optimization process.
It is recommended to read this page in conjunction with those dedicated to the consequences of traditional optimization and a new approach to optimize implant power calculation formulas better.
-Prediction error (PE)
The prediction error (PE) has been defined in the previous section for each eye used to evaluate the formula. It is calculated as the difference between the achieved postoperative refraction (Ra) and the refraction predicted (Rp) by the formula for the IOL power inserted after cataract removal.
PE = Ra – Rp
Example of PE calculation:
The target refraction is -1, and the achieved refraction postoperatively is +0.50:
PE is -1-0.50=-1.50 D
Here is an example of a distribution of Prediction Errors of an IOL power prediction formula (Holladay 1):
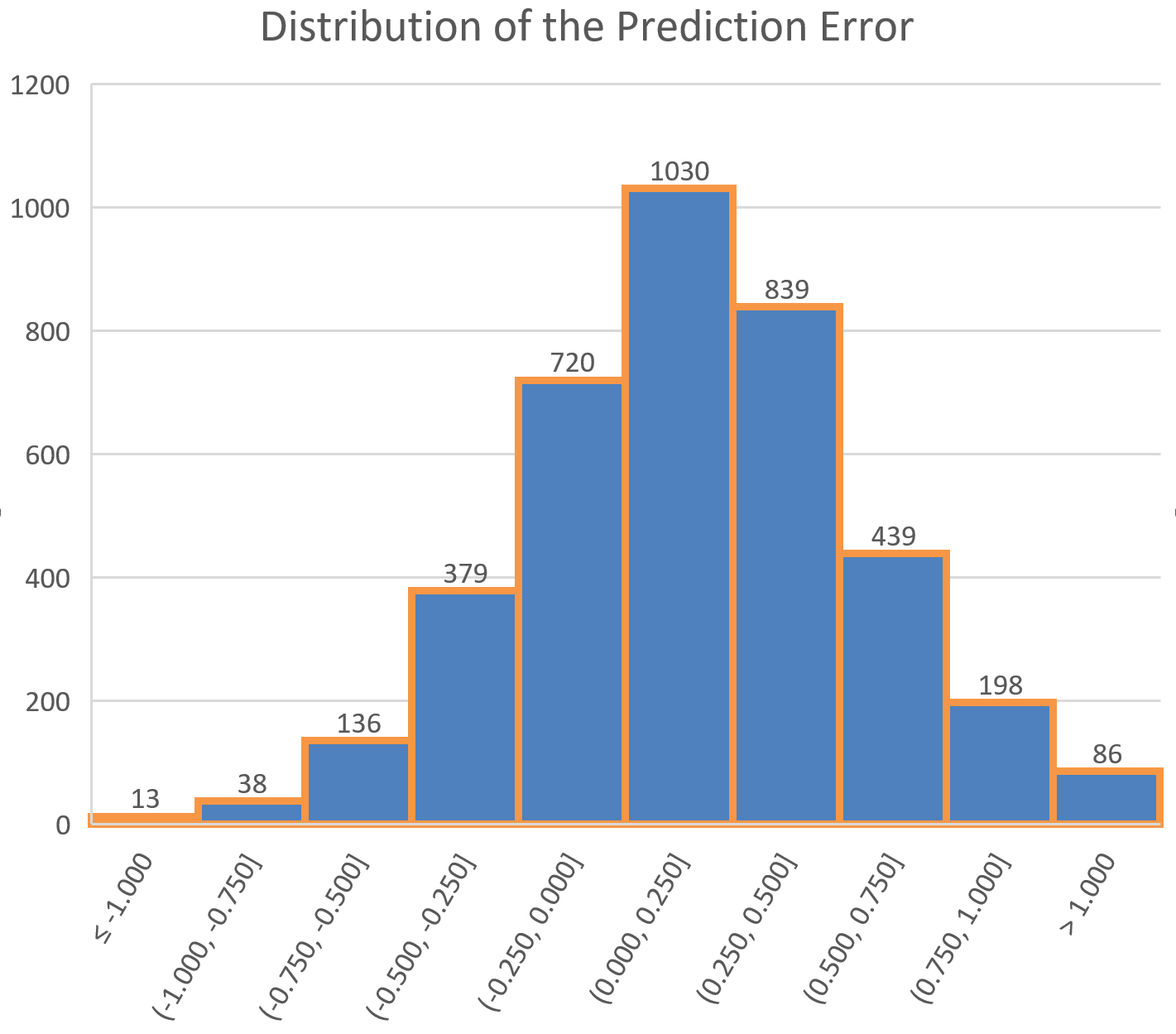
Histogram of the distribution of the Prediction Errors (0.250 D bins) n=3878, Mean Prediction Error : 0.166D, Standard Deviation of the Prediction Error: 0.410 D
A simple approach is to study the distribution of the errors measured on a given sample of eyes: the percentage of eyes for which the prediction error is between +/—0.25D, +/—0.50D, etc.
To obtain these percentages, it is easy first to calculate the absolute value of the PE.
-Absolute value of the Prediction error (PE)
It is given by: |PE| = |Ra – Rp|
Example of |PE| calculation:
The target refraction is -1, and the achieved refraction postoperatively is -0.50:
PE is -1 – (-0.50)=-0.50 D, and |PE|= 0.50 D
This enables to generate of stacked histograms comparing the percentage of eyes within certain prediction error ranges for the IOL power calculation formulas:
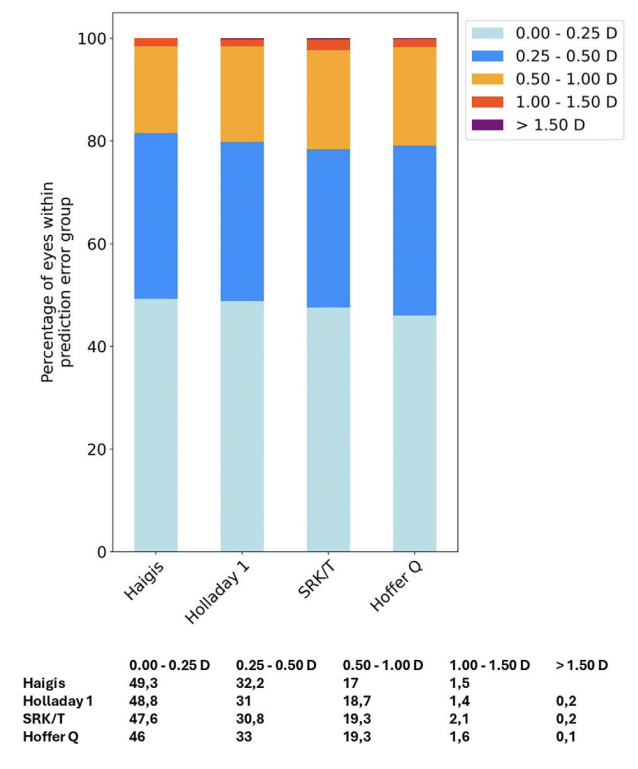
Stacked histograms featuring the % of eyes within certain prediction error ranges for the IOL power calculation formulas.
The higher the percentage of eyes included in the low error groups, the more accurate the formula.
Calculating metrics also allows for quantifying certain properties related to precision and accuracy. Examples will be provided to facilitate understanding of these concepts.
-Range (min-max) of the PE
The range is the difference between the smallest error and the maximum error made by a formula. A large interval suggests intuitively that the dispersion of the PE may be large as well, but there are much better estimators of dispersion. The range only considers the two extreme values and does not account for how the rest of the data is distributed. It can be misleading if outliers exist, so it’s best used alongside other metrics like mean or standard deviation.
The range is intuitive and easy to calculate, offering a quick sense of variability without complex computations. It’s a good starting point for understanding the spread of prediction errors.
The range is the difference between the maximum and minimum values of a dataset. In the context of Prediction Error (PE) for intraocular lens (IOL) power predictions, the range provides insights into the extremes of the prediction performance. Here’s why the range of PE is relevant:
The range tells you the extent of the variation in the prediction errors. While metrics like variance and standard deviation (SD) – see below -give a more nuanced view of the distribution, the range offers a simple way to understand the largest and smallest errors produced by the formula.
The range helps identify outliers or extreme cases. Large ranges often indicate that the model has inconsistencies, producing both accurate and highly inaccurate predictions. The maximum PE highlights the worst-case scenario for the model’s predictions. Knowing the range helps clinicians understand the potential extent of errors in the worst possible situation. If the maximum PE is +4.00 diopters, it means that, in the worst case, the prediction could be 4 diopters off from the target refraction, which could lead to significant postoperative refractive issues.
Example in IOL Power Prediction:
Consider a dataset of Prediction Errors (PE):
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
The minimum PE is -1.00.
The maximum PE is +4.00.
The range is:
Range = 4.00 – (-1.00) = 5.00
This means the prediction errors span 5 diopters, showing that the model sometimes makes very small errors but can also make large ones.
The range of Prediction Errors (PE) provides a simple, straightforward view of the spread of the errors, highlighting the best and worst-case scenarios. While it is useful for identifying outliers and comparing models, it should be used in conjunction with other metrics like standard deviation or variance for a fuller understanding of the model’s performance.
-Mean prediction error (mean PE) :
The mean PE is the average forecast error representing the systematic error of the formula to under (Ra <Rp) or overestimate (Ra > Rp) the postoperative refraction on a set of n eyes.
Mean PE = MBE = (1/n) ∑i=1n (Rai – Rpi)
This value is also referred to as the Mean Bias Error (MBE). The formula expresses that by summing all individual prediction errors (from the first value, i=1 to the last value, i=) and then dividing the total by n, we obtain the average prediction error for the entire dataset.
A non-zero bias indicates a systematic error in the formula, suggesting that it consistently overestimates or underestimates the result.
This bias can be corrected by post-processing the formula, typically through the adjustment of constants, to eliminate the bias and improve the accuracy of future predictions.
-Median of PE
The median is the value separating the higher half from the lower half of a PE sample. It is the middle number, found by ordering all the PE values and picking out the one in the middle (if there are two middle numbers, take the mean of those two numbers).
The median is the value separating the higher half from the lower half of the PE values; it is equivalent to the 2nd quartile, 5th decile, and 50th percentile.
Example of Calculating the Mean and Median for Prediction Error (PE) Values
Let’s consider the following set of Prediction Error (PE) values:
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
(NB: remember these are not the postoperative refractions, but the difference between the achieved and the predicted ones)
Step 1: Calculating the Mean
The mean is the average of all the values in the set. To calculate the mean, we sum all the PE values and divide by the number of values (n = 10):
Mean PE = (-1.00 + (-0.75) + (-0.75) + (-0.50) + (-0.25) + 0.25 + 0.25 + 0.25 + 0.50 + 4.00) / 10
Mean PE = 1.00 / 10 = 0.10
So, the mean Prediction Error is 0.10.
Step 2: Calculating the Median
The median is the middle value of the sorted dataset. To find the median, we arrange the values in order from least to greatest (which is already done here) and then select the middle value. If there is an even number of values, we take the average of the two middle values.
For this dataset, the two middle values (the 5th and 6th values) are -0.25 and +0.25.
Median PE = (-0.25 + 0.25) / 2 = 0
So, the median Prediction Error is 0.
Step 3: Understanding the Difference
In this example, the mean is 0.10, whereas the median is 0. The difference between these two values arises because the mean is more sensitive to extreme values, or outliers, in the dataset. In this case, the value of +4.00 significantly influences the mean, pulling it away from the center of the dataset.
On the other hand, the median is less affected by outliers. It simply reflects the middle value(s) in the sorted dataset and does not take into account the magnitude of extreme values like +4.00. As a result, the median provides a better measure of central tendency in the presence of outliers.
–>The median is often preferred when the dataset contains outliers because it provides a more robust indication of the central value, whereas extreme values can skew the mean. In this example, the outlier value +4.00 raised the mean to 0.10, but the median remained at 0, showing the advantage of the median in this scenario.
-Mean absolute error (MAE).
The MAE is the average of the PE in absolute value.
MAE = (1/n) ∑i=1n |PE| = (1/n) ∑i=1n |Rai – Rpi|
Example: given the Prediction Error (PE) values (same as above)
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
Step 1: Calculate the Absolute Values
| -1.00 | = 1.00, | -0.75 | = 0.75, | -0.75 | = 0.75, | -0.50 | = 0.50, | -0.25 | = 0.25
| +0.25 | = 0.25, | +0.25 | = 0.25, | +0.25 | = 0.25, | +0.50 | = 0.50, | +4.00 | = 4.00
Step 2: Sum the Absolute Values
Sum = 1.00 + 0.75 + 0.75 + 0.50 + 0.25 + 0.25 + 0.25 + 0.25 + 0.50 + 4.00 = 8.50
Step 3: Divide by the Total Number of Values (n = 10)
MAE = 8.50 / 10 = 0.85
–> The Mean Absolute Error (MAE) for this data set is 0.85.
-Median of the absolute value of PE
The median of the PE’s absolute value ( ) is the value separating the higher half from the lower half of the PE’s absolute values.
Like the median itself, the median of absolute values is less influenced by extreme values or outliers in the data. This makes it a more robust measure of central tendency in datasets that contain large deviations. In datasets that do not follow a normal distribution (i.e., those with skewness or heavy tails, such as the distribution of IOL formulas’ PE), the median of absolute values provides a better summary of the central behavior of the data.
When errors are not symmetrically distributed, using the median of absolute errors gives a more accurate picture of the « central » prediction error than using the MAE.
In practice, this is particularly important in fields like medical predictions (such as IOL power predictions), where large outliers may distort averages but are not representative of the majority of predictions.
Example of Median of the Absolute value of PE determination;
Given the Prediction Error (PE) values:
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
Step 1: Calculate the Absolute Values
1.00, 0.75, 0.75, 0.50, 0.25, 0.25, 0.25, 0.25, 0.50, 4.00
Step 2: Sort the Absolute Values
0.25, 0.25, 0.25, 0.25, 0.50, 0.50, 0.75, 0.75, 1.00, 4.00
Step 3: Calculate the Median
The median is the average of the two middle values (5th and 6th values):
Median = (0.50 + 0.50) / 2 = 0.50
–>The median of the absolute values of the Prediction Error (PE) is 0.50.
-Mean Square Error (MSE) –and Root mean square error (RMSE)
The Mean Square Error (MSE) is the sum of the squared prediction errors.
MSE = (1/n) ∑i=1n (Rai – Rpi)2 = (1/n) ∑i=1n PE2
MSE gives us an idea of the magnitude of the errors by squaring them. This penalizes larger errors more heavily than smaller ones, making MSE particularly useful when large errors are especially undesirable. A lower MSE means that the model’s predictions are closer to the actual values. Because the errors are squared, the MSE is always non-negative, and it only equals zero when the predictions are perfect.
Hence, MSE is very sensitive to large errors (outliers). This is useful when we want to emphasize and minimize large errors in a prediction model, as squaring amplifies the effect of large deviations.
The Root Mean Square Error (RMSE) is the square root of the MSE
RMSE = √((1/n) ∑i=1n (Rai – Rpi)2) = √((1/n) ∑i=1n PE2)
RMSE provides a metric that can be interpreted in the same units as the outcome variable (e.g., diopters in the case of IOL power predictions). This makes RMSE easier to interpret than MSE in terms of real-world impact. RMSE, like MSE, is always non-negative and indicates how far off the predictions are, on average. RMSE is one of the most commonly used evaluation metrics in regression problems because it gives a straightforward sense of how far predictions are from the actual values. The lower the RMSE, the better the model’s performance.
Example of MSE and RMSE determination
Given the Prediction Error (PE) values:
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
Step 1: Calculate the Mean Squared Error (MSE)
First, square each error:
1.00, 0.5625, 0.5625, 0.25, 0.0625, 0.0625, 0.0625, 0.0625, 0.25, 16.00
Sum = 18.875
MSE = Sum / 10 = 1.8875
Step 2: Calculate the Root Mean Squared Error (RMSE)
RMSE = √(MSE) = √(1.8875) ≈ 1.3748
–> MSE = 1.8875
–> RMSE = 1.3748
– Variance
Let MBE be the arithmetic mean of the of the prediction error :
Variance = (1/n) ∑i=1n (PEi – MBE)2
It can also be given by:
Variance = (1/n) ∑i=1n PE2 – MBE2
Example of variance calculation:
Given the Prediction Error (PE) values:
{-1.00, -0.75, -0.75, -0.50, -0.25, +0.25, +0.25, +0.25, +0.50, +4.00}
Step 1: Calculate the Mean Bias Error (MBE)
MBE = (-1.00 + (-0.75) + (-0.75) + (-0.50) + (-0.25) + 0.25 + 0.25 + 0.25 + 0.50 + 4.00) / 10
MBE = 0.10
Step 2: Calculate the Squared Differences from the MBE
(-1.00 – 0.10)2 = 1.21 (-0.75 – 0.10)2 = 0.7225 (-0.50 – 0.10)2 = 0.36 (-0.25 – 0.10)2 = 0.1225 (+0.25 – 0.10)2 = 0.0225 (+4.00 – 0.10)2 = 15.21
Step 3: Sum the Squared Differences
Sum = 1.21 + 0.7225 + 0.7225 + 0.36 + 0.1225 + 0.0225 + 0.0225 + 0.0225 + 0.16 + 15.21 = 18.586
Step 4: Calculate the Variance
Variance = 18.586 / 10 = 1.8586
–>The Variance for this data set is 1.8586.
Variance is a key statistical metric that helps quantify the spread or dispersion of data points around the mean. In the context of prediction errors (PE) for models like intraocular lens (IOL) power formulas, variance provides important insights into the model’s performance beyond just the mean error. Here’s why variance is relevant and useful in this specific context
Variance tells us how spread out the prediction errors are from the mean bias error (MBE). While the mean bias (MBE) might be low, indicating that the model performs well on average, a high variance would suggest that the prediction errors fluctuate significantly from the mean.
Low Variance indicates that the prediction errors are consistently close to the mean (low scatter). This suggests the model produces reliable predictions across the dataset.
High Variance indicates that the prediction errors are widely spread out from the mean (high scatter), suggesting inconsistent performance, with some predictions being much further off than others.
The variance can be more useful than the standard deviation when aiming to minimize the SD, as the derivative of the variance is easier to compute. Since the standard deviation is the square root of the variance, minimizing the variance directly simplifies the mathematical process, making it a more efficient approach for optimization.
If two models have the same mean bias error (MBE) but one has a higher variance, the model with the lower variance is preferred because it produces more consistent and reliable predictions, even though both models may have the same average error.
-Standard deviation (SD)
The value of the SD of the PE is obtained as the square root of the variance,
SD = √((1/n) ∑i=1n (PEi – MBE)2)
SD provides a more intuitive, interpretable measure of data variability than variance and is preferred in practical or applied settings (e.g., clinical settings).
The units of measurement are important for directly interpreting the model’s accuracy (e.g., prediction errors in diopters).
Here is an example of two distributions with a different spread around their mean:
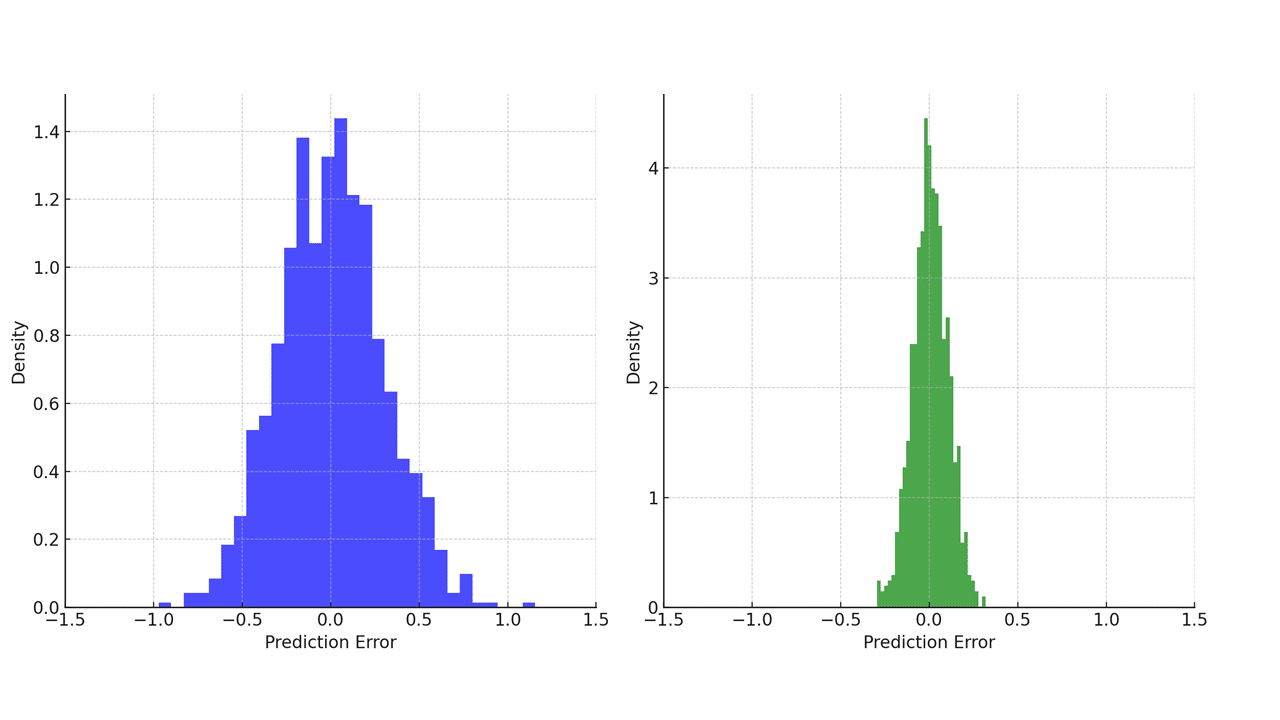
Distributions with different spreads (the SD of the first distribution (in blue) is obviously larger than the one of the second distribution (in green).
Example of SD computation
Using the preceding example, the variance was previously calculated as:
Variance = 1.8586
Step: Calculate the Standard Deviation (SD)
SD = √(Variance) = √(1.8586) ≈ 1.363
–>The Standard Deviation (SD) for this data set is 1.363.
The Standard Deviation (SD) is a crucial metric in statistics, and it plays an especially important role in analyzing prediction errors in models like intraocular lens (IOL) power prediction formulas. In this context, the SD provides key insights into the variability or spread of prediction errors relative to the mean. Here’s why SD is relevant and important:
The SD quantifies the degree of dispersion of prediction errors (PE) around the mean bias error (MBE). While the mean (MBE) gives an average error, it doesn’t tell us how spread out the errors are around that mean. The SD fills this gap by measuring how far the individual errors are from the MBE.
A low SD indicates that most of the prediction errors are clustered closely around the mean, which means the model consistently makes small errors. A low SD means that the prediction errors are similar across different patients, indicating that the model is reliable and predictable.
Conversely, a high SD suggests that the model’s performance varies significantly from one patient to another. Even if the mean error (MBE) is low, a high SD reveals that the model cannot be trusted to perform consistently well across all cases. Hence, a high SD indicates that the prediction errors are widely spread, meaning the model is inconsistent—sometimes, it makes small errors, but other times, it makes very large errors.
We have proposed a new method for optimizing IOL power calculation formulas based on minimizing the SD before zeroing the mean error.
Two important points before concluding:
SD complements the Mean Bias Error (MBE)
The SD complements the mean bias error (MBE) by distinguishing between systematic error (represented by MBE) and non-systematic error (represented by SD). Together, MBE and SD provide a comprehensive picture of model performance:
-MBE tells us whether the model has a systematic bias (e.g., consistently over- or under-predicting).
-SD tells us how much variability or unpredictability exists in the model’s predictions, even if the MBE is low.
For example, if two models have the same MBE but one has a lower SD, the model with the lower SD is preferable because it consistently produces similar errors.
Relation to RMSE
Root Mean Squared Error (RMSE), another key metric, is a combination of both the MBE and the SD:
RMSE = √(MBE2 + SD2)
This formula shows that RMSE increases with both the bias (MBE) and the spread (SD) of the errors. Therefore, reducing the SD directly reduces the RMSE and improves the model’s overall performance.
Laisser un commentaire